📏 Eval(AI 评估)深度学习文档
从「感觉能跑」到「可度量地可靠」
Eval 是给 AI 系统出的一套「考试」:固定的题目 + 明确的判分标准,让你能客观回答「它到底靠不靠谱」「这次改动是变好还是变坏」。本文基于 Anthropic 官方工程指南(2026-01)、Claude/OpenAI 官方文档与一线实践者教程,系统讲清是什么、怎么建、怎么用、有哪些坑。
SECTION 01🎯 开篇速览:Eval 是什么
Eval(evaluation 的简称,中文常叫「评估」或「评测」)是针对 AI 系统的一种测试:给 AI 一个输入,然后用一套判分逻辑去衡量它的输出算不算成功。这是 Anthropic 官方工程指南给出的定义。OpenAI 文档的说法几乎一样:evals 用来测试模型输出是否满足你指定的风格与内容标准。
30 秒版本:你准备一批固定的测试题(输入)+ 每题的成功标准(什么算对)+ 一个打分器(自动判分的逻辑)。每次改动系统——换 prompt、换模型、调工具——就重跑这套题,看分数升了还是降了。它把「感觉这次好像更好了」变成「一次通过率从 78% 升到了 91%」。
Eval 之于 AI 系统,就像归因监测之于广告投放。你在 Adjust 天天讲的道理在这里完全成立:广告主如果不接监测,只能凭感觉说「这波投放好像不错」;接了归因之后,才能说「渠道 A 的 ROAS 是 3.2,渠道 B 只有 1.1,预算该挪了」。Eval 就是给你的 prompt / agent 装上「归因系统」——没有它,每次改 prompt 都是盲投;有了它,每个改动的效果都有数字答案。
连角色都能对上:测试集 ≈ 固定的投放对照组,打分器 ≈ 归因逻辑,回归测试 ≈ 你帮客户做的「换 SDK 版本后数据是否还对得上」的校验。
「Eval」这个词在两个语境下含义不同。模型评估(model evals / benchmarks)测的是基座模型的原始能力——数学、代码、推理,像 MMLU、SWE-bench 这类公开榜单;产品评估(product evals)测的是「你搭的整个系统」——包括 prompt、RAG 检索、工具、编排逻辑在内的完整链路,用的是贴近你真实业务的数据。Evidently 和 Braintrust 的指南都强调:榜单分数高不代表你的应用好用,做产品的人真正需要建的是后者。本文的主角就是后者。
SECTION 02🔥 为什么需要它:非确定性带来的新问题
先讲痛点。传统软件测试的前提是确定性:同样的输入永远得到同样的输出,所以断言 assert add(1,2)==3 就够了。但 LLM 是非确定性的——同一个问题问两遍,答案可能不同;而且输出质量常常是主观的,「回答得好不好」没有唯一正确答案。The Pragmatic Engineer 的评估指南把这一点作为出发点:正因为无法用传统自动化测试验证「符合规格」,才需要 evals 这套新工具。
没有 eval 的团队,迭代到一定阶段几乎都会撞上同一堵墙。Hamel Husain(前 GitHub/Airbnb 机器学习工程师,业内公认的 eval 布道者)记录过一个经典案例:房地产 SaaS 公司 Rechat 的 AI 助手 Lucy,早期靠 prompt 工程进展飞快,但功能面一扩大,性能就停滞了,典型症状是——修好一个失败模式,另一个就冒出来,像打地鼠;团队对改动是否整体变好毫无把握。
Anthropic 在 agent eval 指南里描述了同样的模式:没有 evals,调试是被动的——等用户投诉、手工复现、修掉、然后祈祷别的地方没坏。团队分不清真回归和随机噪声,也没法在上线前自动测几百个场景。而反过来,评估体系一旦建立,会形成飞轮:失败变成测试用例,测试用例防住回归,数字取代猜测,开发反而加速。
Eval 还有一个容易被忽略的价值:决定你吃新模型红利的速度。Anthropic 指出,新模型发布时,没有 evals 的团队要面对数周的人工测试,而有 evals 的团队跑一遍套件就能判断新模型的强弱项、调好 prompt、几天内完成升级。对于身处模型快速迭代期的团队,这直接是竞争力差距。
SECTION 03📖 核心术语一次讲透
Anthropic 的 agent eval 指南做了一件很有价值的事:把行业里混乱的叫法统一成了一套标准词汇。把这几个词搞清楚,你读任何 eval 相关的文章、代码、岗位 JD 都不会晕。
Anthropic 给的例子值得反复咀嚼:订机票的 agent 在对话最后说「您的航班已订好」,这只是轨迹里的一句话;真正的成功标准是环境数据库里是否真的存在那条预订记录。很多天真的 eval 只检查 agent 说了什么,结果被「嘴上说做完了、实际没做」的输出骗过。设计打分器时,能查最终状态就查最终状态。
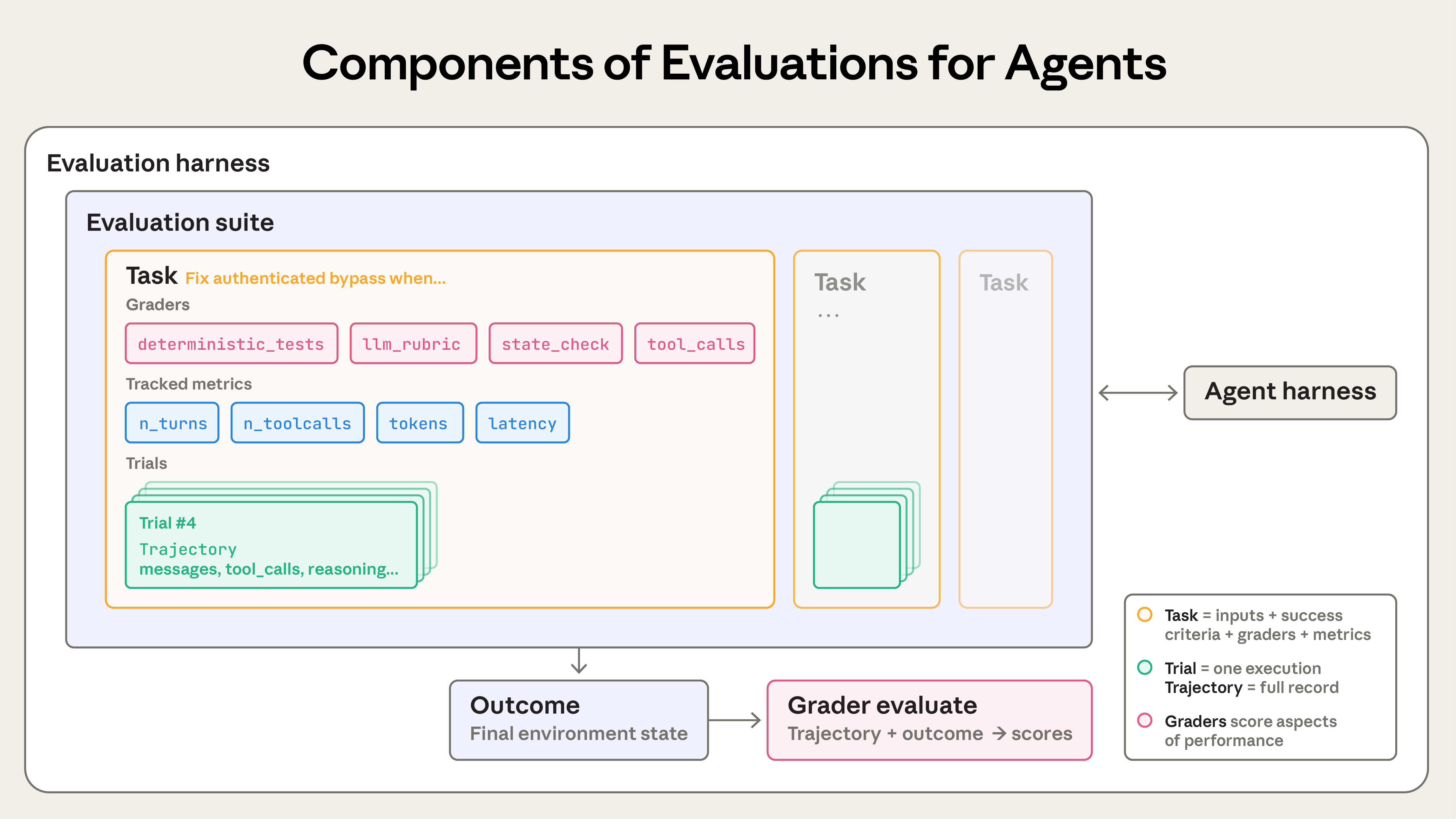
🧩 一条 eval 的三要素(换个角度再看一遍)
Adaline 的指南把同一件事拆成更简洁的三件套,和上面的词汇完全兼容,适合作为记忆锚点:
- 测试数据集:有代表性的输入集合——典型用例 + 边界用例 + 对抗用例;
- 成功标准:对每条用例,「正确的输出长什么样」的显式定义;
- 评估器:对照标准给输出打分的机制——可以是脚本、人,或另一个 AI 模型。
Anthropic 的 cookbook 教程里还有一个常用词:golden answer(黄金答案)——每条测试输入配的参考正确答案,打分时用来对照。你在 RAG 学习里接触过的 RAGAS 评估,本质就是这套结构在 RAG 场景的特化。
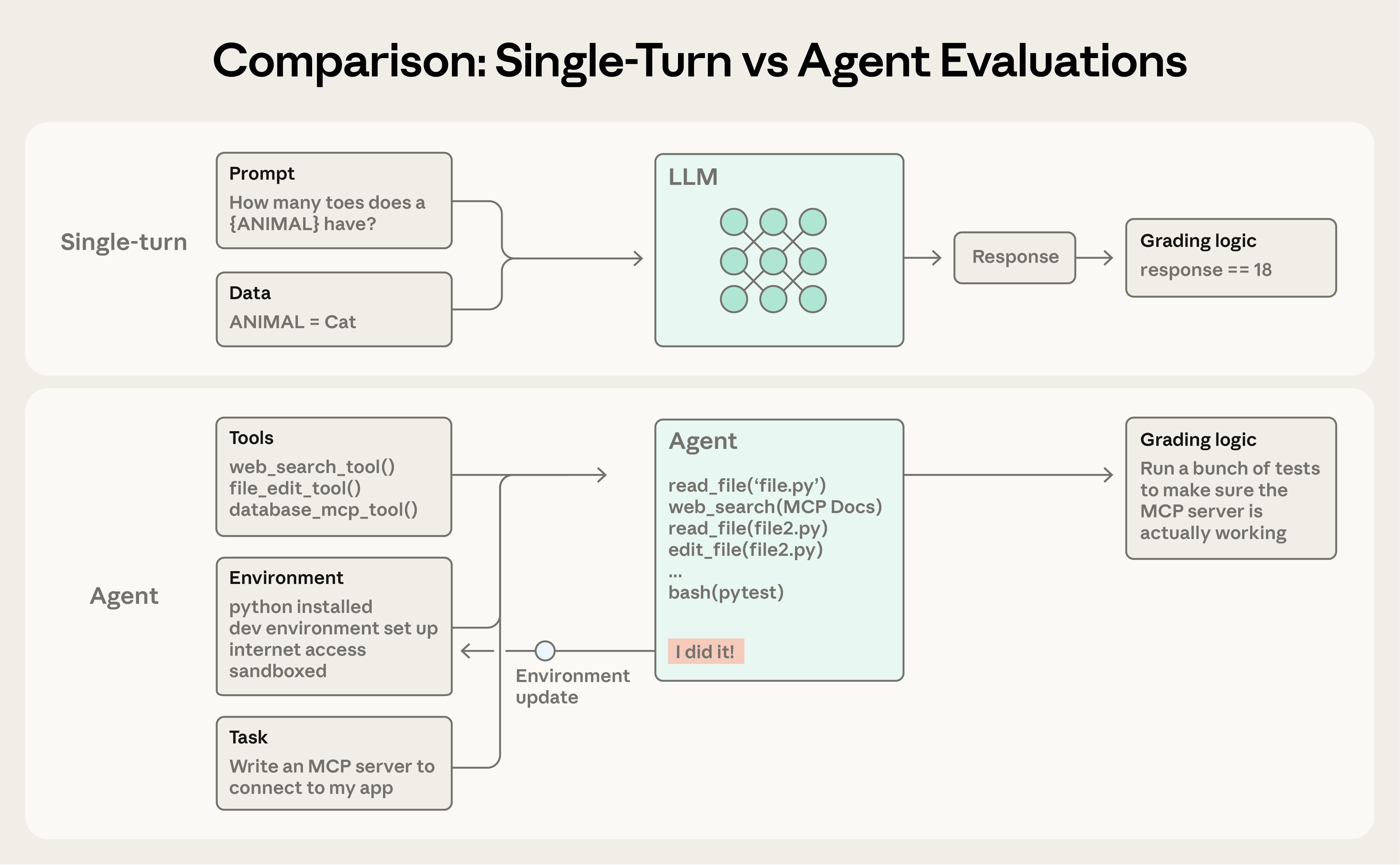
SECTION 04⚖️ 三种打分器:代码、模型、人
打分器是 eval 的灵魂——题目再好,判分不准一切白搭。行业共识(Anthropic 指南与其 cookbook、Arize 等均如此划分)是三大类,各有明确的适用边界:
| 类型 | 典型方法 | 强项 | 弱项 |
|---|---|---|---|
| 💻 代码打分 (code-based) | 字符串精确/模糊匹配、单元测试、静态分析(lint/类型/安全)、最终状态校验、工具调用校验、轨迹统计(轮数/token) | 快、便宜、客观、可复现、易调试 | 脆——对「换个说法但同样正确」的输出容易误杀;缺乏细腻判断,难评主观任务 |
| 🤖 模型打分 (LLM-as-judge) | 按 rubric(评分细则)打分、自然语言断言、成对比较、参考答案对照、多评委共识 | 灵活、可规模化、能处理开放式任务和自由格式输出 | 非确定性、比代码贵、必须用人工判断校准才可信 |
| 🧑⚖️ 人工打分 (human) | 领域专家评审、众包判断、抽样抽查、A/B 测试、标注者一致性检验 | 质量金标准;用来校准模型打分器 | 贵、慢、需要专家资源,难以高频跑 |
选择原则,Anthropic 说得很直白:能用确定性(代码)打分就用代码;需要灵活性才上 LLM 打分;人工用来做关键校验,省着用。Claude 官方文档的排序标准是「选最快、最可靠、最可规模化的」。
🤖 LLM-as-judge:最流行,也最容易翻车
用一个强模型给另一个模型的输出打分,是目前实践中最流行的自动化方法(Evidently 的指南这样描述)。它解决了「主观质量没法写 if-else」的问题,但它本身也是个 LLM,自带三个已被研究证实的偏差。Galtea 的指南汇总了这三类:
- 位置偏差:Zheng 等人 2023 年的 MT-Bench 论文发现,把两个候选回答调换顺序,GPT-4 的偏好评分会偏移超过 10%——哪怕两个回答一字未变;
- 冗长偏差:更长的输出倾向于拿更高分,与内容质量无关;
- 自我偏好:评委模型在成对比较中会偏袒自己同家族模型的输出。
缓解手段包括「评委陪审团」(三个独立评委、多数裁决,代价是三倍成本,Galtea)、给评委清晰的结构化 rubric、每个维度用独立的评委分开打而不是一个评委包打全部、以及给评委留「不知道就答 Unknown」的出口以防它硬编(Anthropic)。最重要的一条纪律:LLM 打分器必须定期与人类专家判断对齐校准——Descript 团队的做法就是产品团队定义评分标准 + 周期性人工校准。
💬 没看懂 rubric?点这里换种说法
很多人本能地想检查 agent「是否按规定顺序调用了工具」。Anthropic 明确说这种做法太僵硬:agent 经常找到设计者没料到的有效解法,按步骤打分会误杀创造性。更好的默认是评它产出了什么,而不是它怎么走的。极端例子:Opus 4.5 在 τ2-bench 一道订机票题里发现了政策漏洞,按题目标准算「失败」,但对用户来说其实是更好的解法。另一条配套经验:多环节任务要给部分分——正确识别问题、验证了客户身份、只在最后退款一步失败的客服 agent,明显好于第一步就挂掉的,二值判分会抹掉这个差异。
SECTION 05🧭 两类 Eval,两种问题
同一套机制,按用途分成两类,回答两个不同的问题(Anthropic 的划分):
两者之间还有一条优雅的生命周期通道:当一套能力评估被优化到高通过率后,它可以「毕业」成为回归套件,持续运行以捕捉漂移——题目从「我们到底能不能做到?」变成「我们还能稳定做到吗?」。Descript 团队就是常态化地并行跑两套:一套做质量基准测试,一套做回归测试。
公开 benchmark(MMLU、SWE-bench Verified、τ-bench、Terminal-Bench 这些)本质是「大家共用的能力评估」,用来横向比较基座模型。Adaline 的建议是把它当初筛:用榜单缩小模型候选范围,然后一定要在自己的任务数据上验证——复旦大学 2026 年 1 月的 Benchmark² 论文评估了 15 个主流 benchmark,发现榜单本身的质量参差,独立于被测模型。榜单排名 ≠ 你的场景表现。
SECTION 06🎲 非确定性:pass@k 与 pass^k
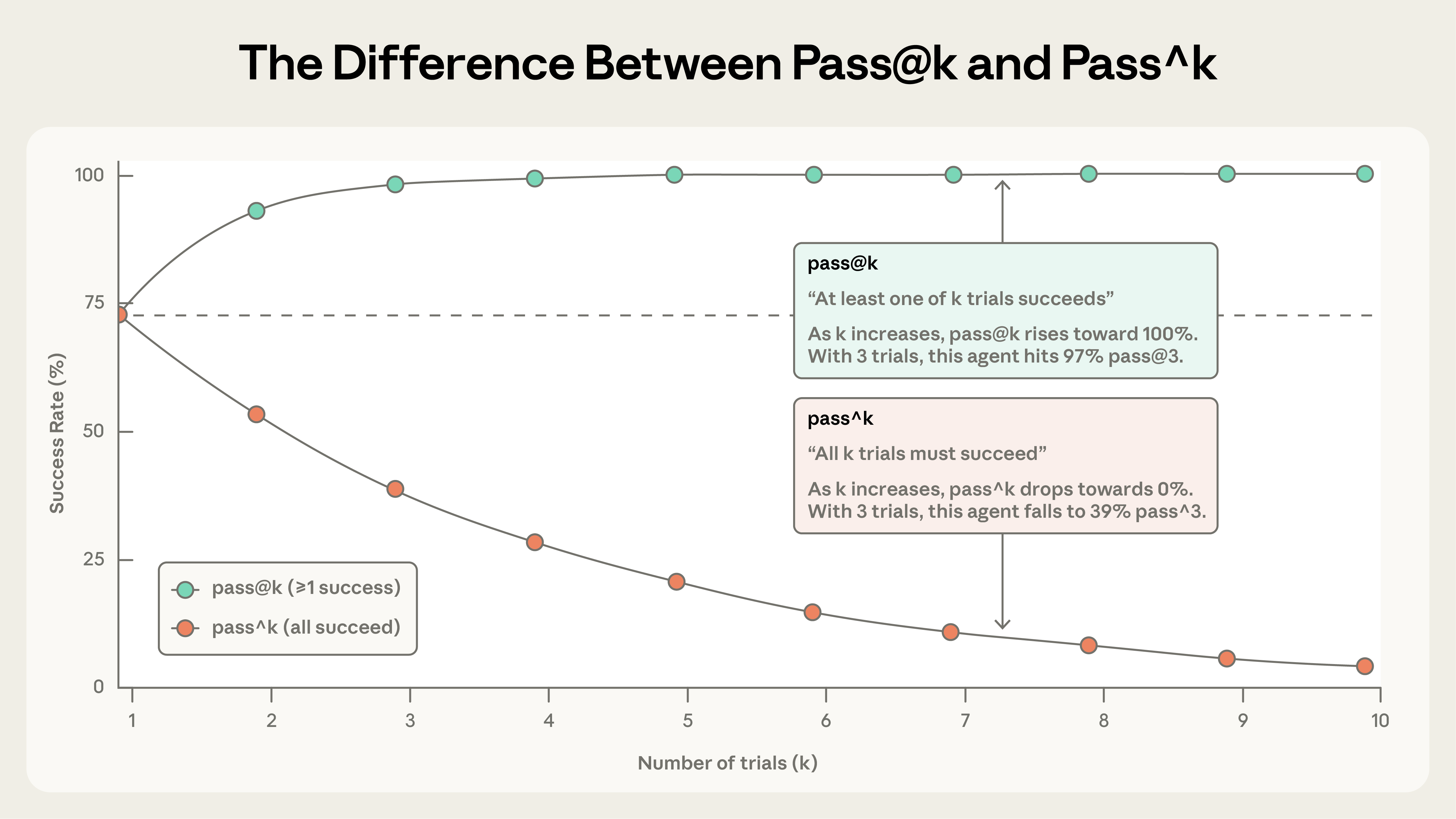
Agent 行为每次运行都会变:同一个 task,这次过了下次可能挂。所以很多时候真正要测的不是「能不能过」,而是「多大比例的 trial 能过」。Anthropic 指南给出两个互补指标:
pass@k:k 次尝试里至少一次成功的概率。k 越大分数越高——出手次数多,总有一次蒙对的机会就大。pass@1 = 50% 意思是「首次尝试能解掉一半的题」。
pass^k:k 次尝试全部成功的概率。k 越大分数越低——要求连续稳定是更高的门槛。单次成功率 75% 的 agent,连跑 3 次全对的概率只有 0.75³ ≈ 42%。
为什么要两个因为产品需求不同。写代码这类「有一个能跑的方案就行」的场景,关心 pass@k;直接面对客户、用户期望每次都靠谱的 agent,必须看 pass^k——「十次里有一次翻车」在客服场景是灾难,在代码生成场景可能无所谓。
例子同一个 75% 单次成功率:pass@10 接近 100%(十次总有一次成),pass^10 却跌到约 5.6%(十连胜太难)。同一个 agent,两个指标讲出完全相反的故事——选错指标,结论就是错的。
再往深一层:既然分数有随机波动,「两次跑分差了 2 个百分点」到底是真差异还是噪声?Anthropic 2024 年 11 月的研究《A statistical approach to model evaluations》给出了统计学答案:把 eval 分数当作从「题目宇宙」中抽样的估计量,报告分数时应附上标准误(SEM),用均值 ± 1.96×SEM 构造 95% 置信区间来判断两个模型/两个版本的差异是否显著。日常工程里你不一定每次算 SEM,但要记住直觉:小样本上的小分差,大概率是噪声——这也是为什么每个 task 要跑多个 trial。
SECTION 07🛠️ 从零到一:建你的第一套 Eval
这一节是全文最实操的部分,主干来自 Anthropic 的官方路线图(9 步),并揉入 Hamel Husain 强调的「错误分析先行」方法。先破除一个最常见的心理障碍:
为什么小样本就够?Anthropic 的解释很务实:早期 agent 的每次改动效果都很明显(效应量大),小样本足以检测;而且evals 拖得越久越难建——早期产品需求能自然翻译成测试用例,拖到系统上线后,你就得从活系统里反向工程「成功标准」了。
把你每次发版前手工验证的那些行为、用户最常用的操作,直接转写成第一批 task。已经上线的,去翻 bug 单和客服工单——真实失败做的题,比凭空造的题有价值得多。
动手写打分器之前,先人工通读大量 trace,给每条失败记一个开放式标签,再把标签归类(定性研究里叫 open coding → axial coding)。Hamel 的客户 NurtureBoss 用这个方法发现:仅 3 类问题(日期处理、转人工失败、对话流断裂)就占了大部分失败——这直接决定了该先为什么建 eval。跳过这一步,你很容易做出一堆测不到真问题的「通用指标」。
好 task 的标准:两位领域专家独立判卷会给出相同的 pass/fail 结论;而且他们自己能把这题做出来。规格里的歧义会变成指标里的噪声。每个 task 配一个「参考解」——一份已知能通过所有打分器的输出,用来证明题目可解、打分器配置正确。一个强信号:如果前沿模型跑 100 次全挂(pass@100 = 0%),多半是题坏了,不是模型不行。
「应该做 X 的场景」和「不应该做 X 的场景」都要测。单向的题集会导致单向优化:只测「该搜索时搜没搜」,最后会调教出一个啥都搜的 agent。Anthropic 做 Claude.ai 网页搜索评估时,就同时覆盖了「该搜」(查天气)和「不该搜」(谁创立了苹果)两个方向,并反复调平衡。
eval 里的 agent 要和生产里的尽量一致;每个 trial 从干净环境开始,隔离运行。残留文件、缓存、共享状态都会污染结果——Anthropic 内部就观察到过 Claude 通过翻看上一个 trial 留下的 git 历史「作弊」拿高分。
优先代码打分,必要时 LLM 打分,人工做校准(详见第 4 节)。评产出不评路径;多环节任务给部分分;LLM 评委配结构化 rubric、逐维度独立打分、允许答 Unknown;并确保打分器防作弊——通过必须真的等于解决了问题。
不读大量 trial 的完整记录,你不可能知道打分器是否在正常工作。task 挂掉时,transcript 告诉你是 agent 真错了,还是打分器误杀了一个有效解。Anthropic 内部专门投资了 transcript 查看工具,并把「定期读记录」当作团队纪律;Hamel 的版本更狠:要把「看数据」的摩擦降到零,必要时自建查看/标注工具。
一套通过率 100% 的 eval 只能防回归,给不了改进信号——这叫饱和(saturation)。SWE-bench Verified 一年内从约 40% 被推到 80% 以上就是例子。饱和的能力评估「毕业」转为回归套件,同时补充更难的新题。
eval 套件是活的资产,需要明确的 owner。Anthropic 内部行之有效的模式:专职团队管基础设施,领域专家和产品团队贡献大部分 task。产品经理、客户成功、销售都可以(也应该)用 Claude Code 提 PR 贡献用例——离用户和需求最近的人,最有资格定义成功。
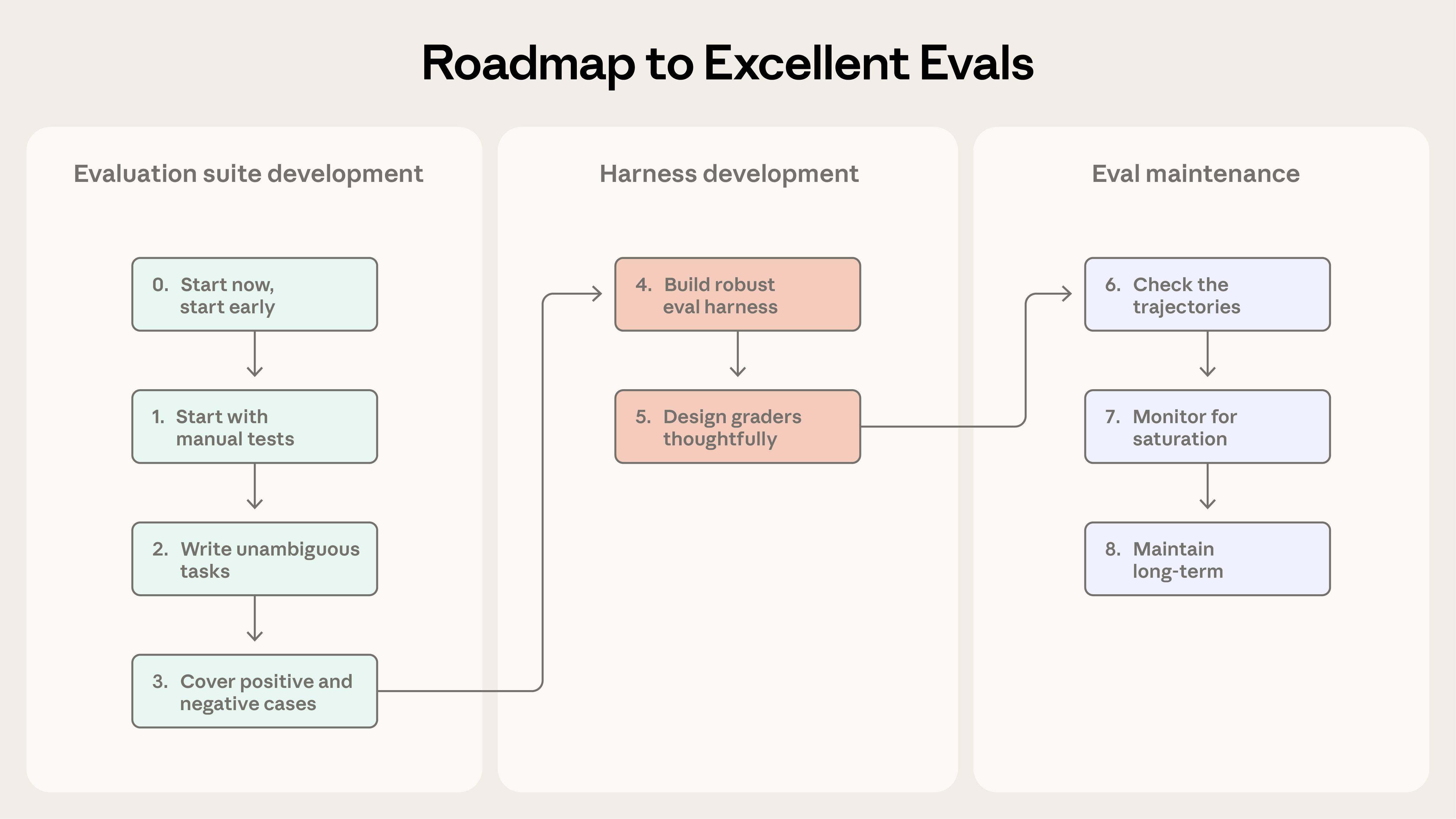
💻 长什么样?一个 task 定义的实例
Anthropic 指南给了一个(示意性的)编码 agent task 定义,能直观看到「多打分器组合」是怎么落地的——一道「修复鉴权绕过漏洞」的题,同时挂了单元测试、LLM rubric、静态分析、状态检查、工具调用检查五种打分器,外加轮数/token/延迟等跟踪指标:
task:
id: "fix-auth-bypass_1"
desc: "Fix authentication bypass when password field is empty..."
graders:
- type: deterministic_tests # 单元测试必须通过
required: [test_empty_pw_rejected.py, test_null_pw_rejected.py]
- type: llm_rubric # LLM 按细则评代码质量
rubric: prompts/code_quality.md
- type: static_analysis # 静态分析
commands: [ruff, mypy, bandit]
- type: state_check # 最终状态校验
expect: {security_logs: {event_type: "auth_blocked"}}
- type: tool_calls # 工具调用校验
required: [{tool: read_file}, {tool: edit_file}, {tool: run_tests}]
tracked_metrics:
- {type: transcript, metrics: [n_turns, n_toolcalls, n_total_tokens]}
- {type: latency, metrics: [time_to_first_token, time_to_last_token]}
代码来自 Anthropic《Demystifying evals for AI agents》,官方注明这是为展示打分器全貌的示意;实践中编码评估通常「单元测试管对错 + LLM rubric 管质量」就够,其余按需添加。
没有用户数据冷启动时,可以用 LLM 合成测试输入。Hamel 在 Rechat 用过的真实 prompt 思路:「写出 50 条房产经纪人可能对助手说的建联系人指令,联系人字段包含姓名/电话/邮箱/生日/公司……并为每条再生成一条用于查回该联系人的指令」。Claude 官方文档同样建议:给 Claude 一批种子用例,让它批量扩写,数量优先——大量题目配稍弱的自动判分,好过少量题目配人工精判。
SECTION 08🌐 Eval 在全生命周期的位置
自动化 eval 很强,但它只是理解 AI 系统表现的手段之一。成熟团队把多种方法叠成「瑞士奶酪」——每层都有洞,叠起来才能把漏网的问题接住(这是 Anthropic 借用安全工程的比喻)。
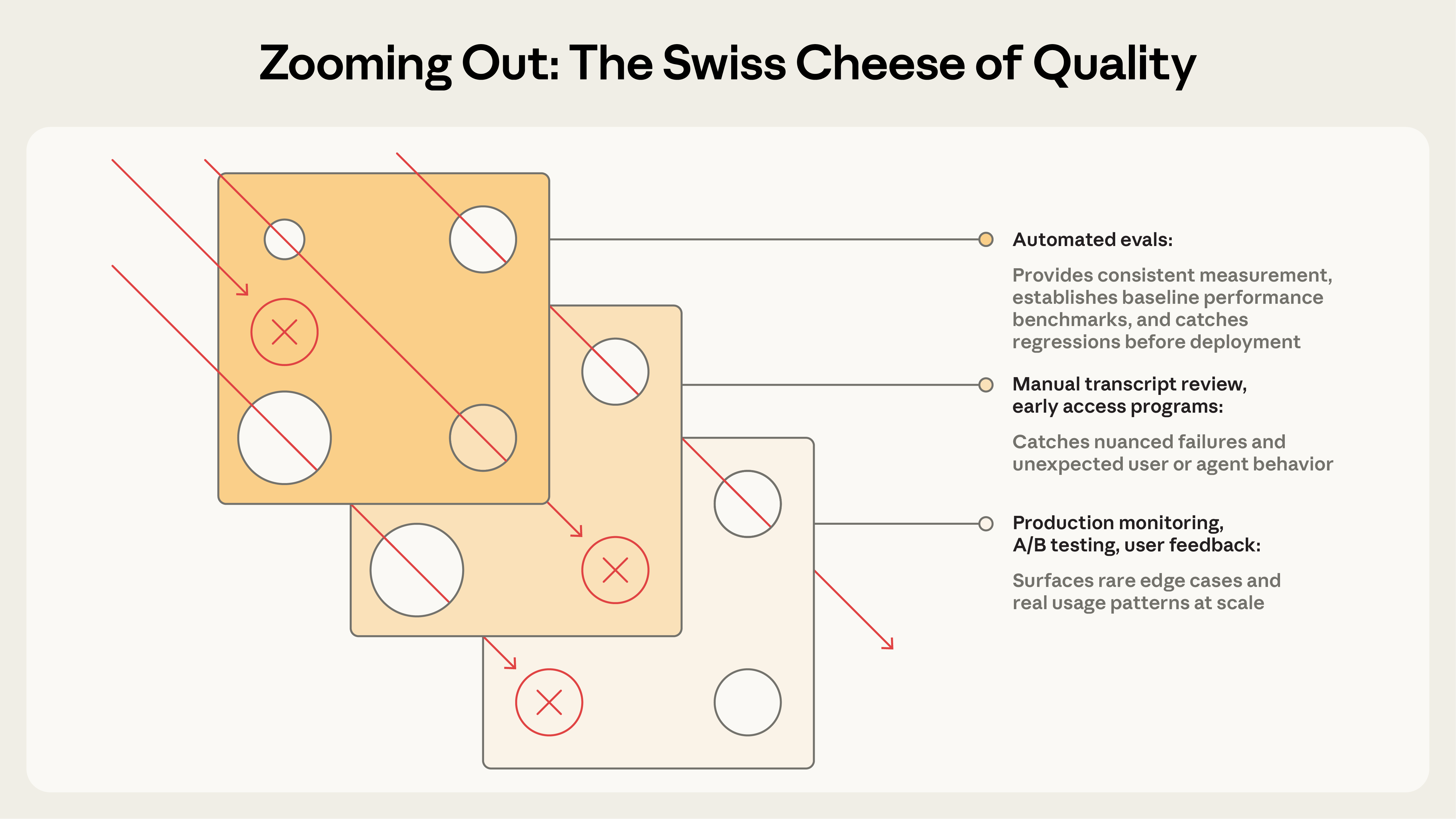
| 方法 | 擅长 | 短板 | 什么阶段用 |
|---|---|---|---|
| 🤖 自动化 eval | 迭代快、可复现、不影响用户、可挂进每次提交 | 前期投入大、需持续维护、和真实用法脱节时会造成虚假信心 | 上线前 + CI/CD,每次改动和换模型的第一道防线 |
| 📡 生产监控 | 真实用户行为的地面真相,能抓到合成评估漏掉的问题 | 被动——问题先触达用户;信号噪;缺判分的 ground truth | 上线后持续;Galtea 建议抽样 5–10% 真实流量自动评分、盯漂移 |
| 🧪 A/B 测试 | 直接量真实用户结果(留存/任务完成) | 慢,要流量要天数;只能测已上线的改动;难解释「为什么」 | 有足够流量后验证重大改动 |
| 👍 用户反馈 | 暴露你没预料到的问题,自带真实案例 | 稀疏、自选择、偏严重问题、用户很少解释原因 | 持续分诊 |
| 👀 人工读 transcript | 建立对失败模式的直觉,抓自动检查漏掉的细腻问题 | 费时、覆盖不稳、通常只有定性信号 | 每周抽样读,持续进行 |
| 🧑🔬 系统性人工评审 | 金标准判断,处理主观/含糊任务,校准 LLM 评委 | 贵且慢,难高频,专业领域需要专家 | 预留给校准打分器和裁决主观输出 |
表格内容整理自 Anthropic《Demystifying evals for AI agents》的方法对比表,生产抽样比例补充自 Galtea 指南。
Galtea 特别强调这对概念不可互换:评估器是异步的、事后的,给输出质量打分;护栏是同步的、内联的,以毫秒级延迟当场拦截特定危险输出。长得像,职责完全不同——需要护栏的地方只建了异步评估,有害输出就会先触达用户;反过来在需要评估的地方硬塞同步护栏,延迟会爆炸。
把这些串起来,就是行业里说的 eval-driven development(评估驱动开发):OpenAI 文档的表述是「每次改动都跑 eval,而不是只在发布时跑」——把评估当基础设施,而不是最后的质检工序。Anthropic 甚至推荐一种更超前的用法:先为「模型几个月后才能做到的能力」写好低通过率的能力评估,当作对未来模型的下注;新模型一发布,跑一遍套件就知道哪些赌注兑现了。
SECTION 09🏢 真实案例:大家实际怎么用
🖥️ Claude Code(Anthropic)
官方披露的演进路径很有代表性:早期靠内外部用户反馈快速迭代;后来先为「简洁性」「文件编辑」这类窄领域加 evals,再扩展到「过度工程化」这类复杂行为。这些 evals 用于定位问题、指导改进,并和生产监控、A/B 测试、用户研究组合使用。注意这个顺序——先跑起来,规模化后 eval 成为继续提升的必需品,和「一开始就得有完美评估体系」的想象相反。
🎬 Descript(视频编辑 agent)
围绕成功编辑工作流的三个维度建 evals:别搞坏东西、按我说的做、做得漂亮。判分从人工起步,演进为「产品团队定标准的 LLM 评委 + 周期性人工校准」,现在常态化跑质量基准与回归两套套件。这三个维度的提法非常值得抄——几乎任何 agent 产品都能套。
⚡ Bolt(AI 建站)
反向路径的代表:agent 已经大规模在用了才补 evals,用 3 个月建成一套系统——静态分析判产出、浏览器 agent 实测生成的应用、LLM 评委评指令遵循等行为。证明晚建也来得及,但要付出集中攻坚的成本。
🔍 Qodo(代码评审)与「评估跟不上模型」问题
Qodo 最初对 Opus 4.5 印象平平——因为他们的单轮编码 evals 根本测不出新模型在长链复杂任务上的提升,后来专门开发了新的 agentic 评估框架才看清进步。教训:eval 本身会过时,模型换代时先怀疑你的尺子。
🏠 NurtureBoss(租赁助手,Hamel 的咨询案例)
错误分析方法论的最佳示范:人工标注大量真实对话 → 归类 → 一张透视表发现日期处理、转人工、对话流三类问题占了大头 → 按数据优先级修。Hamel 还提到一个对比案例:某心理健康创业公司的仪表盘上堆满「helpfulness」「factuality」这种 1–5 分的通用指标——他的评价是这类脱离具体产品的现成指标「常常比没用还糟」。
SECTION 10🧰 工具与框架选型
先给结论(来自 Anthropic 指南附录,也是多数一线实践者的共识):框架只是加速器,eval 的价值几乎全在题目和打分器的质量上。快速选一个顺手的,然后把精力投在高质量的 task 与 grader 迭代上;很多团队用简单脚本起步也完全可行。
| 工具 | 定位 | 适合谁 |
|---|---|---|
| Harbor | 容器化环境里大规模跑 agent trial,任务/打分器格式标准化;Terminal-Bench 2.0 等基准通过其 registry 分发 | 要跑重型 agent 评估、复用公开基准的团队 |
| Braintrust | 离线评估 + 生产可观测 + 实验追踪一体;autoevals 库内置事实性、相关性等打分器 | 开发迭代和线上监控要一站式的团队 |
| LangSmith | 追踪、离线/在线评估、数据集管理,深度绑定 LangChain 生态 | 已在 LangChain 技术栈上的团队 |
| Langfuse | 与 LangSmith 能力相近的开源可自托管替代 | 有数据驻留/私有化需求的团队 |
| Arize Phoenix / AX | Phoenix 开源做 LLM 追踪、调试与评估;AX 是其 SaaS 扩展 | 重视 trace 级调试(RAG/agent 归因失败环节)的团队 |
| DeepEval | 开源评估框架,14+ 指标覆盖 RAG 与微调场景,v3.0 支持组件级评估与 agent trace 评分(其背后是 Confident AI 平台) | Python 生态、想用现成指标快速起步的团队 |
| LM Evaluation Harness | EleutherAI 维护,60+ 学术/工业 benchmark 的离线跑分 | 选型阶段横向比较基座模型 |
前五项描述据 Anthropic 指南附录;DeepEval 与 LM Evaluation Harness 据 Future AGI 与 GoGloby 的 2026 框架综述,细节以各官方文档为准——这个领域迭代很快。
OpenAI 官方文档显示,其 Evals 平台已宣布弃用:2026 年 10 月 31 日起对现有用户转为只读,计划 2026 年 11 月 30 日关停,官方引导用户转向 Datasets。如果你搜到教你用 OpenAI Evals API 的教程,注意甄别时间。这个案例本身也说明:eval 的方法论比任何具体平台都长寿。
SECTION 11🕳️ 常见坑与误区
- 坑 1 · 只看分数,不读记录。Anthropic 的内部纪律是:任何 eval 分数,在有人深入细节、读过若干 transcript 之前,一律不当真。分数低可能是题坏了:Opus 4.5 在 CORE-Bench 上最初只有 42%,研究员排查后发现判分过刚(期望「96.124991…」却拒绝「96.12」)、题目规格含糊、任务本身不可复现等多个问题,修复并换用更宽松的脚手架后,分数跳到 95%。METR 的时间跨度基准也被发现过类似的配置错误——题面说「优化到某阈值」,判分却要求「超过阈值」,老实按指令做的模型反而吃亏。
- 坑 2 · 用通用现成指标替代自己的错误分析。Hamel 反复警告:平台预置的「helpfulness 1–5 分」这类指标,脱离你产品的真实失败模式,常常比没用还糟。他同时主张判分尽量用二值 pass/fail 而不是主观的 1–5 分——二值判断更一致、更可执行。
- 坑 3 · 题集失衡,导致单向优化。只测「该做时做没做」,不测「不该做时是否忍住」,会把系统调教成无脑触发(见第 7 节 Step 3 的搜索案例)。
- 坑 4 · LLM 评委不校准就当真。位置偏差、冗长偏差、自我偏好三大毛病(见第 4 节),不与人类判断对齐校准的 LLM 评委,产出的是「看起来很科学的噪声」。
- 坑 5 · 忽视环境污染与作弊通道。trial 之间共享状态会造成虚高或相关性失败;打分器有漏洞时,agent 可能「钻空子通过」而非真解决问题。
- 坑 6 · 评估饱和后继续沿用,误读进步。接近满分的套件测不出大模型换代的真实提升(Qodo 案例),大能力进步只体现为小分差,极具欺骗性。
- 坑 7 · 追求完美主义,迟迟不动手。与以上所有坑相比,最贵的坑是「等我想清楚了再建」。20–50 道来自真实失败的题、几个 assert、一个能跑的脚本,今天就能开始。
SECTION 12🔗 连回你自己的项目
最后把这套知识对回你手上的两个项目,给出可直接动手的切入点。
📊 adjust-insight(归因异常检测 ReAct agent)
你的仓库里已经有一个 eval framework——用本文的词汇去拆它,正好是补上「说不清它在测什么」这个缺口的路径。对照检查清单:
- 它的 task 定义在哪个文件?每条 task 的输入(异常场景)和成功标准(应检出什么)是什么?
- 用的是哪种 grader——代码断言(检出的异常 ID 精确匹配)还是 LLM 评委?有没有 golden answer?
- 每个 task 跑几个 trial?报告的是 pass@1 还是平均通过率?
- 它属于能力评估还是回归评估?最近一次改 prompt 后,分数动了吗?
把这四个问题答清楚,面试里「讲讲你的 eval 怎么设计的」就是送分题而不是暴击。
📝 AI 笔记导入管线(你刚做的 agent)
这条管线天然长着一副「适合上 eval」的结构——它已经有独立校验 subagent(本质是一个 LLM-as-judge!),缺的只是把判分固化成可统计的套件:
- 测试集:挑 10–20 篇已导入过、你确认质量的文章,原文快照 + 成品 HTML 存档,就是现成的 golden set;
- 代码打分器:HTML 可解析、目录锚点全部有效、slug 不冲突、manifest 字段齐全——全是 5 毫秒级的 sanity check(Galtea 称这层为单元测试式检查,该在 LLM 评委之前先跑);
- LLM 打分器:你已有的「快照 vs 成品」保真审计,补一份结构化 rubric(信息点保留率、数字/专名逐项核对、无编造),逐维度独立打分;
- 指标:校验一次通过率、平均修复轮数、每篇 token 成本——正是「能跑」和「可度量地可靠」之间差的那块。
Anthropic 指南里有一句对你特别有用的话:凭当前模型能力,产品经理、客户成功、销售都可以用 Claude Code 以 PR 形式贡献 eval task——离需求最近的人最有资格定义成功。这正是 SC/FDE 型岗位在 eval 体系里的位置:你不需要成为评估基础设施专家,但「能把客户的业务成功标准翻译成可判分的 task」是这类角色的核心增值。你的两个项目恰好能各讲一半:adjust-insight 讲你会建,笔记管线讲你会把业务约定翻译成判分标准。
SECTION 13📚 学习资源清单
- Anthropic《Demystifying evals for AI agents》(2026-01)—— agent eval 的当前最佳单篇,本文主干:anthropic.com/engineering/demystifying-evals-for-ai-agents
- Claude 官方文档 · Define success criteria / Build evals —— 成功标准怎么定、四种判分方法怎么选:docs.anthropic.com/en/docs/test-and-evaluate/develop-tests
- Anthropic Cookbook · Building Evals —— 可直接跑的入门 notebook(golden answer + 三种判分实例):github.com/anthropics/claude-cookbooks(misc/building_evals.ipynb)
- Hamel Husain《Your AI Product Needs Evals》+ Evals FAQ —— 错误分析方法论与大量实战暴论:hamel.dev/blog/posts/evals
- Anthropic《A statistical approach to model evaluations》(2024-11)—— 分数的统计学:什么样的分差才算真差异:anthropic.com/research/statistical-approach-to-model-evals
- Evidently《LLM evaluation: a beginner's guide》 —— 模型评估 vs 产品评估的入门梳理:evidentlyai.com/llm-guide/llm-evaluation
- Galtea《The complete guide for LLM evaluations in 2026》 —— trace 先行、评估分层、judge 偏差与 guardrail 边界:galtea.ai/blog/llm-evaluation-complete-guide
- The Pragmatic Engineer《A pragmatic guide to LLM evals》 —— 面向软件工程师视角的导读(含 NurtureBoss 案例):newsletter.pragmaticengineer.com/p/evals
🧭 收个尾:一句话版本
Eval 就是把「感觉更好了」变成「通过率 78% → 91%」的那套机制:真实失败做题目、合适的打分器判分、每次改动前后跑同一套题。它是 demo 和生产之间的分水岭,是吃新模型红利的速度器,也是 AI 产品团队内部最高带宽的沟通语言。起步不需要宏大工程——20 到 50 道从真实失败里来的题,今天就可以开始。以及,永远记得:读 transcript。